

还剩24页未读,
继续阅读
信息技术必修1 数据与计算5.3.1 特征探索教学演示ppt课件
展开
这是一份信息技术必修1 数据与计算5.3.1 特征探索教学演示ppt课件,共32页。PPT课件主要包含了3数据分析,什么是数据分析,李海青,数据分析,31特征探索,缺失值,异常值,数据清洗,数据特征探索程序,32关联分析等内容,欢迎下载使用。
高中信息技术必修1 数据与计算
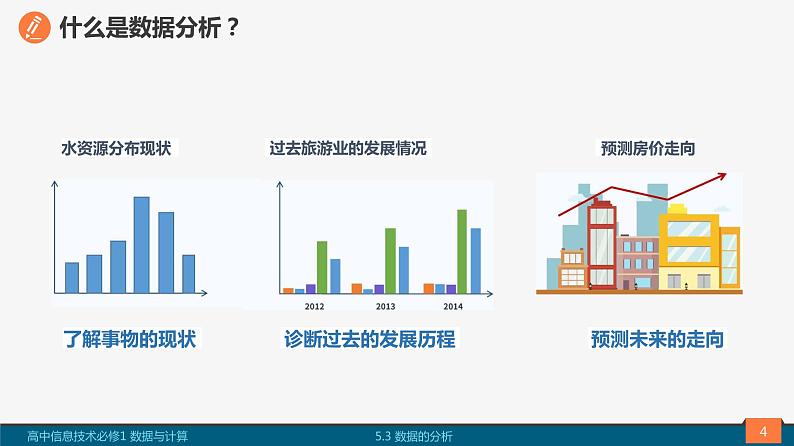
数据分析是在一大批杂乱无章的数据中,运用数字化工具和技术,探索数据内在的结构和规律,构建数学模型,并进行可视化表达,通过验证将模型转化为知识,为诊断过去、预测未来发挥作用。
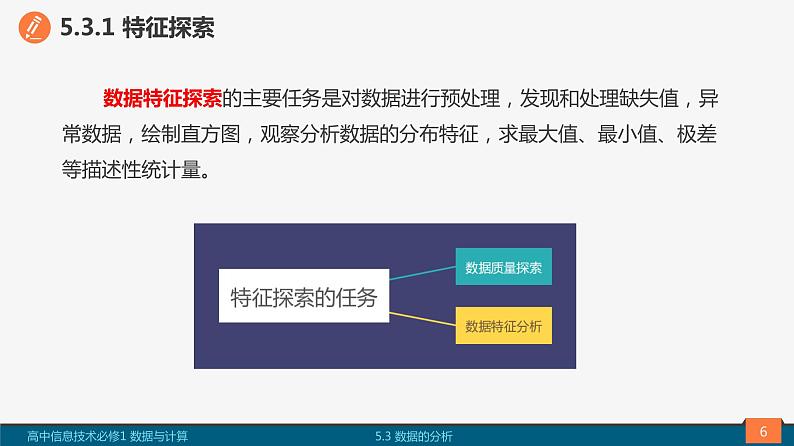
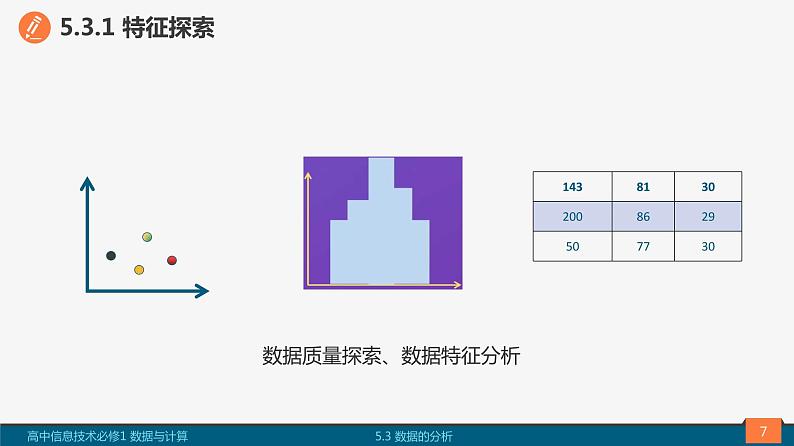
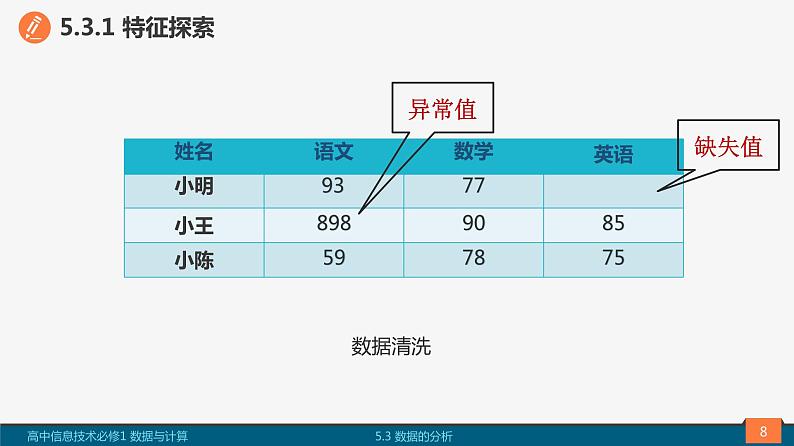
数据特征探索的主要任务是对数据进行预处理,发现和处理缺失值,异常数据,绘制直方图,观察分析数据的分布特征,求最大值、最小值、极差等描述性统计量。
数据质量探索、数据特征分析
探究活动一(暂停课程视频5分钟): 打开并运行配套学习资源包“第五章\课本素材\程序5-3数据预处理”,观察数据预处理结果。
关联分析就是分析并发现存在于大量数据之间的关联性或相关性,从而描述一个事物中某些属性同时出现的规律和模式。
购物篮分析一一了解顾客购买习惯一一给商家提供销售策略
计算机如何对数据进行关联分析?
步骤一:扫描数据,建立项集
步骤二:计算各个集合的支持度,即数据出现频率次数/总数
步骤三:设置最小支持度=0.4
步骤三:设置最小支持度=0.4
C1项集 支持度[可乐] 3/4=0.75[鸡蛋] 1/4=0.25[火腿] 2/4=0.50[尿布] 3/4=0.75[啤酒] 3/4=0.75
[可乐] [火腿][尿布][啤酒]
C2项集 支持度[可乐,火腿] 2/4=0.50[可乐,尿布] 2/4=0.50[可乐,啤酒] 2/4=0.50[火腿,尿布] 1/4=0.25[火腿,啤酒] 1/4=0.25[尿布,啤酒] 3/4=0.75
[可乐,火腿] [可乐,尿布][可乐,啤酒][尿布,啤酒]
步骤四:将L1中的数据两两拼接
C2项集 支持度[可乐,火腿] 2/4=0.50[可乐,尿布] 2/4=0.50[可乐,啤酒] 2/4=0.50[火腿,尿布] 1/4=0.25[火腿,啤酒] 1/4=0.25[尿布,啤酒] 3/4=0.75
C3项集 支持度[可乐,火腿,尿布] 2/4=0.50[可乐,火腿,啤酒] 2/4=0.50[可乐,尿布,啤酒] 2/4=0.50
步骤五:将L2中的数据两两拼接,得到C3
探究活动二(暂停课程视频5分钟): 理解关联分析的过程,根据下表,按步骤计算商品的关联性。
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。
K-平均算法的基本思想就是在空间N个点中,初始选择K个点作为中心聚类点,然后将N个点分别与K个点计算距离,选择自己最近的点作为自己的中心点,再不断更新中心聚集点,以达到“物以类聚,人以群分”的效果。
聚类分析的基本算法:(1)从数据点集合中随机选择K个点作为初始的聚集中心,每个中心点代表着每个聚集中心的平均值。(2)对其余的每个数据点,依次判断其与K个中心点的距离,距离最近的表明它属于这项聚类。(3)重新计算新的聚簇集合的平均值即中心点。整个过程不断迭代计算,直到达到预先设定的迭代次数或中心点不再频繁波动。
数据分类是数据分析处理中最基本的方法。数据分类通常的做法是,基于样本数据先训练构建分类函数或者分类模型(也称为分类器),该分类器具有将待分类数据项映射到某一特点类别的功能。数据分类和回归分析都可用于预测,预测是指从基于样本数据记录,根据分类准则自动给出对未知数据的推广描述,从而实现对未知数据进行预测。
贝叶斯分类技术在众多分类技术中占有重要地位,也属于统计学分类的范畴,是一种非规则的分类方法。贝叶斯分类技术通过对已分类的样本子集进行训练,学习归纳出分类函数(对离散变量的预测称作分类,对连续变量的分类称为回归),利用训练得到的分类器实现对未分类数据的分类。
如表所示是某网络商城客户购物行为特征的一组统计资料。已知某客户购物行为特征A为数值182.8,特征B为数值58.9,特征C为数值26,请问这人是重要客户还是普通客户?
imprt numpy as npX=np.array([[182.8,81.6,30],[180.4,86.1,29],[170.0,77.1,30],[180.4,74.8,28],[152.4,45.3,24],[167.6,68.0,26],[165.2,58.9,25],[175.2,68.0,27]])Y=np.array([1,1,1,1,0,0,0,0])frm sklearn.naive_bayes imprt GaussianNBclf=GaussianNB().fit(X,Y)print(clf.predict([[182.8,58,9,26]]))
程序结果为:[0]为普通客户
高中信息技术必修1 数据与计算
数据分析是在一大批杂乱无章的数据中,运用数字化工具和技术,探索数据内在的结构和规律,构建数学模型,并进行可视化表达,通过验证将模型转化为知识,为诊断过去、预测未来发挥作用。
数据特征探索的主要任务是对数据进行预处理,发现和处理缺失值,异常数据,绘制直方图,观察分析数据的分布特征,求最大值、最小值、极差等描述性统计量。
数据质量探索、数据特征分析
探究活动一(暂停课程视频5分钟): 打开并运行配套学习资源包“第五章\课本素材\程序5-3数据预处理”,观察数据预处理结果。
关联分析就是分析并发现存在于大量数据之间的关联性或相关性,从而描述一个事物中某些属性同时出现的规律和模式。
购物篮分析一一了解顾客购买习惯一一给商家提供销售策略
计算机如何对数据进行关联分析?
步骤一:扫描数据,建立项集
步骤二:计算各个集合的支持度,即数据出现频率次数/总数
步骤三:设置最小支持度=0.4
步骤三:设置最小支持度=0.4
C1项集 支持度[可乐] 3/4=0.75[鸡蛋] 1/4=0.25[火腿] 2/4=0.50[尿布] 3/4=0.75[啤酒] 3/4=0.75
[可乐] [火腿][尿布][啤酒]
C2项集 支持度[可乐,火腿] 2/4=0.50[可乐,尿布] 2/4=0.50[可乐,啤酒] 2/4=0.50[火腿,尿布] 1/4=0.25[火腿,啤酒] 1/4=0.25[尿布,啤酒] 3/4=0.75
[可乐,火腿] [可乐,尿布][可乐,啤酒][尿布,啤酒]
步骤四:将L1中的数据两两拼接
C2项集 支持度[可乐,火腿] 2/4=0.50[可乐,尿布] 2/4=0.50[可乐,啤酒] 2/4=0.50[火腿,尿布] 1/4=0.25[火腿,啤酒] 1/4=0.25[尿布,啤酒] 3/4=0.75
C3项集 支持度[可乐,火腿,尿布] 2/4=0.50[可乐,火腿,啤酒] 2/4=0.50[可乐,尿布,啤酒] 2/4=0.50
步骤五:将L2中的数据两两拼接,得到C3
探究活动二(暂停课程视频5分钟): 理解关联分析的过程,根据下表,按步骤计算商品的关联性。
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。
K-平均算法的基本思想就是在空间N个点中,初始选择K个点作为中心聚类点,然后将N个点分别与K个点计算距离,选择自己最近的点作为自己的中心点,再不断更新中心聚集点,以达到“物以类聚,人以群分”的效果。
聚类分析的基本算法:(1)从数据点集合中随机选择K个点作为初始的聚集中心,每个中心点代表着每个聚集中心的平均值。(2)对其余的每个数据点,依次判断其与K个中心点的距离,距离最近的表明它属于这项聚类。(3)重新计算新的聚簇集合的平均值即中心点。整个过程不断迭代计算,直到达到预先设定的迭代次数或中心点不再频繁波动。
数据分类是数据分析处理中最基本的方法。数据分类通常的做法是,基于样本数据先训练构建分类函数或者分类模型(也称为分类器),该分类器具有将待分类数据项映射到某一特点类别的功能。数据分类和回归分析都可用于预测,预测是指从基于样本数据记录,根据分类准则自动给出对未知数据的推广描述,从而实现对未知数据进行预测。
贝叶斯分类技术在众多分类技术中占有重要地位,也属于统计学分类的范畴,是一种非规则的分类方法。贝叶斯分类技术通过对已分类的样本子集进行训练,学习归纳出分类函数(对离散变量的预测称作分类,对连续变量的分类称为回归),利用训练得到的分类器实现对未分类数据的分类。
如表所示是某网络商城客户购物行为特征的一组统计资料。已知某客户购物行为特征A为数值182.8,特征B为数值58.9,特征C为数值26,请问这人是重要客户还是普通客户?
imprt numpy as npX=np.array([[182.8,81.6,30],[180.4,86.1,29],[170.0,77.1,30],[180.4,74.8,28],[152.4,45.3,24],[167.6,68.0,26],[165.2,58.9,25],[175.2,68.0,27]])Y=np.array([1,1,1,1,0,0,0,0])frm sklearn.naive_bayes imprt GaussianNBclf=GaussianNB().fit(X,Y)print(clf.predict([[182.8,58,9,26]]))
程序结果为:[0]为普通客户
相关课件
高中粤教版 (2019)1.2.2 编码的基本方式背景图ppt课件: 这是一份高中粤教版 (2019)1.2.2 编码的基本方式背景图ppt课件,文件包含53数据的分析-新教材粤教版2019高中信息技术必修一课课件28pptx、53数据的分析-新教材粤教版2019高中信息技术必修一课练习docx等2份课件配套教学资源,其中PPT共28页, 欢迎下载使用。
高中粤教版 (2019)5.3.1 特征探索优质课件ppt: 这是一份高中粤教版 (2019)5.3.1 特征探索优质课件ppt,共18页。PPT课件主要包含了学习目标,重难点,课堂导入,项目实施等内容,欢迎下载使用。
粤教版 (2019)必修1 数据与计算第五章 数据处理和可视化表达5.3 数据的分析本节综合与测试评优课课件ppt: 这是一份粤教版 (2019)必修1 数据与计算第五章 数据处理和可视化表达5.3 数据的分析本节综合与测试评优课课件ppt,共23页。PPT课件主要包含了31特征探索,32关联分析,2寻找关联规则,33聚类分析,34数据分类等内容,欢迎下载使用。












